SPI服务发现机制实现
SPI机制实现
什么是SPI机制?
SPI(Service Provider Interface),是JDK内置的一种 服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用,比如java.sql.Driver接口,其他不同厂商可以针对同一接口做出不同的实现,MySQL和PostgreSQL都有不同的实现提供给用户,而Java的SPI机制可以为某个接口寻找服务实现。Java中SPI机制主要思想是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要,其核心思想就是 解耦。

当服务的提供者提供了一种接口的实现之后,需要在classpath下的META-INF/services/目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体的实现类。当其他的程序需要这个服务的时候,就可以通过查找这个jar包(一般都是以jar包做依赖)的META-INF/services/中的配置文件,配置文件中有接口的具体实现类名,可以根据这个类名进行加载实例化,就可以使用该服务了。JDK中查找服务的实现的工具类是:java.util.ServiceLoader。
Java SPI 就是提供了这样一个机制:为某个接口寻找服务实现的机制。这有点类似 IoC 的思想,将装配的控制权移交到了程序之外。
系统SPI实现(Demo)
如图,我们在com.yunfei.rpc.spi目录下面 建三个类,
public interface Animal {
void eat(String food);
}
public class Cat implements Animal{
@Override
public void eat(String food) {
System.out.println("Cat eat"+ food);
}
}
public class Dog implements Animal {
@Override
public void eat(String food) {
System.out.println("Dog eat " + food);
}
}
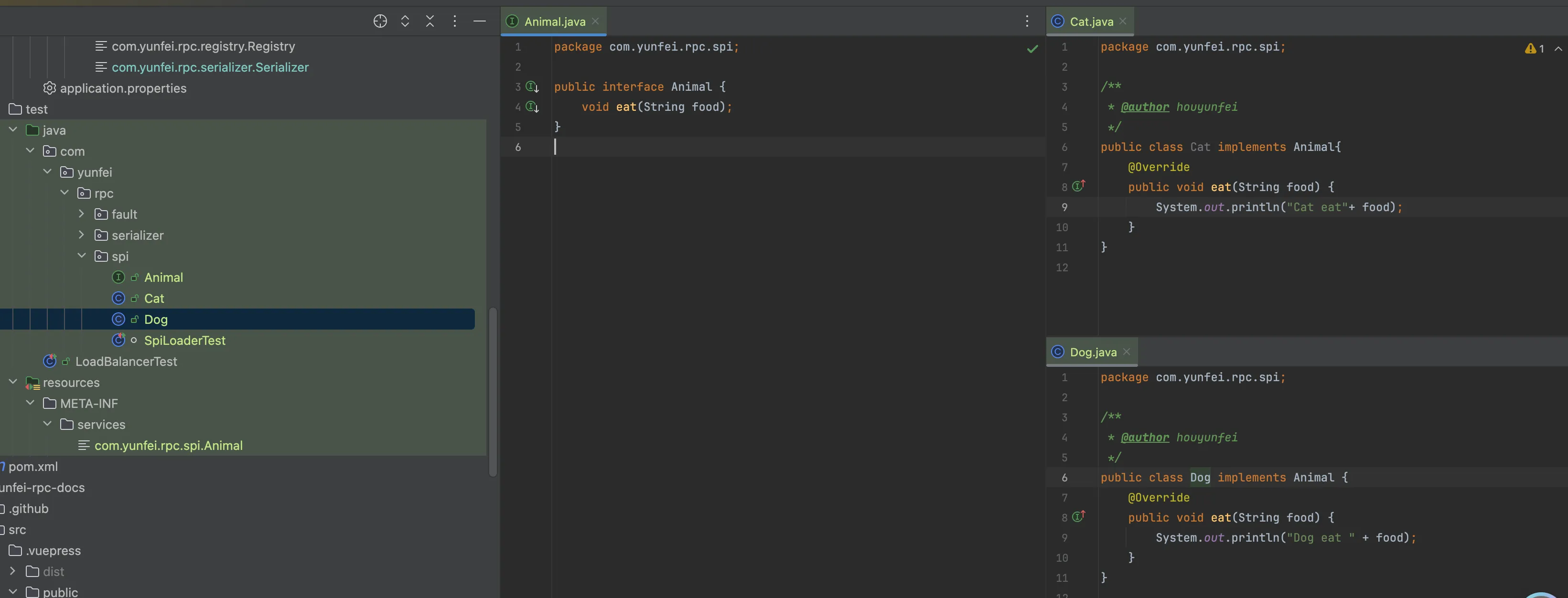
然后我们在META-INF/services目录下面去新建一个文件com.yunfei.rpc.spi.Animal,这个文件是接口全限定名的文件,里面放上我们需要用到的实现类
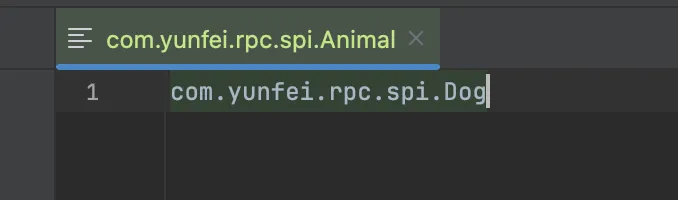
我在这里写的是狗,而不是猫,然后编写测试代码:
public static void main(String[] args) throws Exception {
ServiceLoader<Animal> animalServiceLoader = ServiceLoader.load(Animal.class);
for (Animal animal : animalServiceLoader) {
animal.eat("shit");
}
}
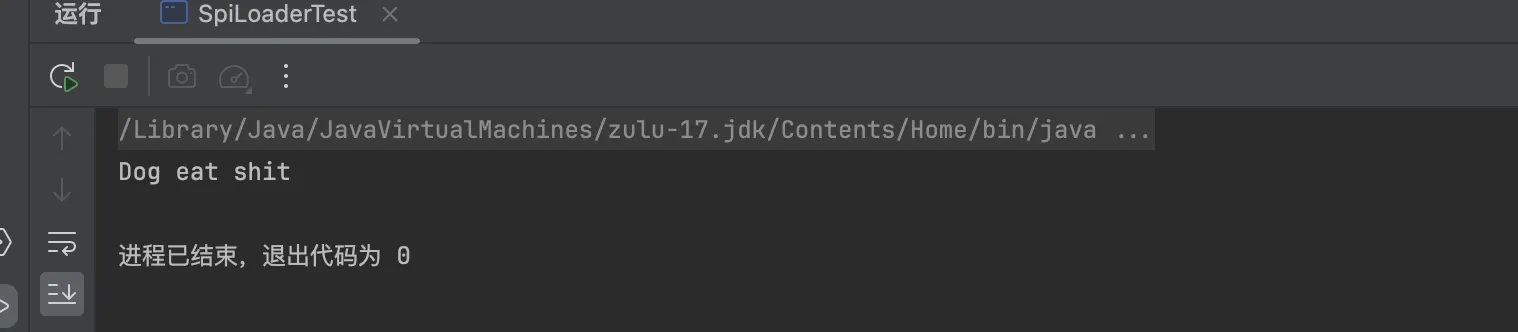
成功加载:
现在,我在里面写两个实现类:
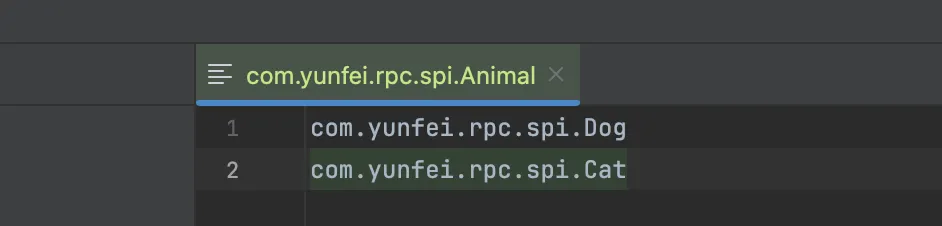
运行结果:
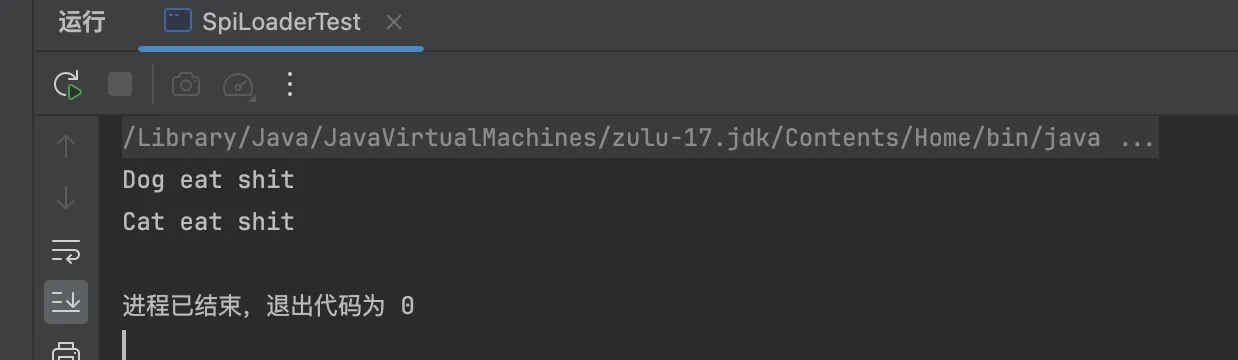
我们发现,现在就是两个类都可以加载了,这就是spi的思想,接口的实现由provider实现,provider只用在提交的jar包里的META-INF/services下根据平台定义的接口新建文件,并添加进相应的实现类内容就好。
SPI机制的应用场景
以下为一些具体的应用场景,我们开发中国呢经常用到的框架基本都使用了java的SPI机制
| 应用名称 | 具体应用场景 |
|---|---|
| 数据库驱动程序加载 | JDBC为了实现可插拔的数据库驱动,在Java.sql.Driver接口中定义了一组标准的API规范,而具体的数据库厂商则需要实现这个接口,以提供自己的数据库驱动程序。在Java中,JDBC驱动程序的加载就是通过SPI机制实现的。 |
| 日志框架的实现 | 流行的开源日志框架,如Log4j、SLF4J和Logback等,都采用了SPI机制。用户可以根据自己的需求选择合适的日志实现,而不需要修改代码。 |
| Spring框架 | Spring框架中的Bean加载机制就使用了SPI思想,通过读取classpath下的META-INF/spring.factories文件来加载各种自定义的Bean。 |
| Dubbo框架 | Dubbo框架也使用了SPI思想,通过接口注解@SPI声明扩展点接口,并在classpath下的META-INF/dubbo目录中提供实现类的配置文件,来实现扩展点的动态加载。 |
| MyBatis框架 | MyBatis框架中的插件机制也使用了SPI思想,通过在classpath下的META-INF/services目录中存放插件接口的实现类路径,来实现插件的加载和执行。 |
| Netty框架 | Netty框架也使用了SPI机制,让用户可以根据自己的需求选择合适的网络协议实现方式。 |
| Hadoop框架 | Hadoop框架中的输入输出格式也使用了SPI思想,通过在classpath下的META-INF/services目录中存放输入输出格式接口的实现类路径,来实现输入输出格式的灵活配置和切换。 |
Spring的SPI机制相对于Java原生的SPI机制进行了改造和扩展,主要体现在以下几个方面:
- 支持多个实现类:Spring的SPI机制允许为同一个接口定义多个实现类,而Java原生的SPI机制只支持单个实现类。这使得在应用程序中使用Spring的SPI机制更加灵活和可扩展。
- 支持自动装配:Spring的SPI机制支持自动装配,可以通过将实现类标记为Spring组件(例如@Component),从而实现自动装配和依赖注入。这在一定程度上简化了应用程序中服务提供者的配置和管理。
- 支持动态替换:Spring的SPI机制支持动态替换服务提供者,可以通过修改配置文件或者其他方式来切换服务提供者。而Java原生的SPI机制只能在启动时加载一次服务提供者,并且无法在运行时动态替换。
- 提供了更多扩展点:Spring的SPI机制提供了很多扩展点,例如BeanPostProcessor、BeanFactoryPostProcessor等,可以在服务提供者初始化和创建过程中进行自定义操作。
自定义SPI机制实现
- 指定SPI的配置目录位置
系统内置的SPI机制会加载resources/META-INFO/services目录,我们自定义的目录位置可以放在resources/META-INFO/rpc,还可以在这个目录下面继续细分,用户自定义SPIrpc/custom,我们系统内置的SPI:rpc/custom
- 在配置文件中编写我们之前实现的类,如序列化器
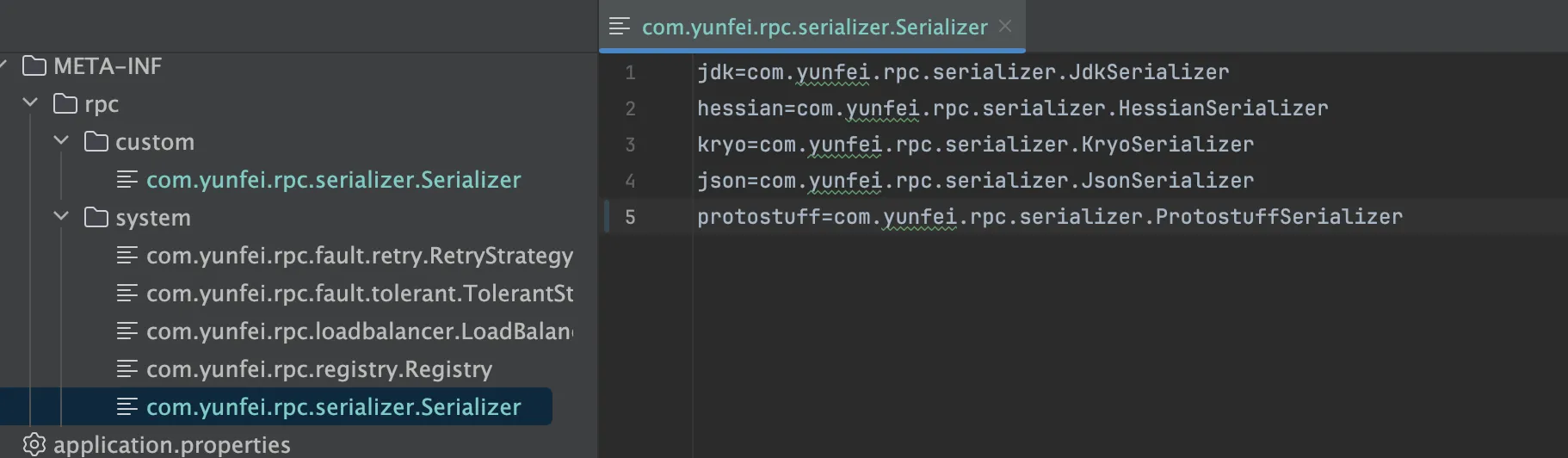
格式为:key=value
- 编写工具类,用来读取配置并加载实现类的方法
package com.yunfei.rpc.spi;
import cn.hutool.core.io.resource.ResourceUtil;
import com.yunfei.rpc.serializer.Serializer;
import lombok.extern.slf4j.Slf4j;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* SPI加载器 (支持键值对映射)
*/
@Slf4j
public class SpiLoader {
/**
* 存储已加载的类:接口名=>(key=>实现类)
*/
private static Map<String, Map<String, Class<?>>> loaderMap = new ConcurrentHashMap<>();
/**
* 对象实例缓存 避免重放new 类路径=> 对象实例 ,单例模式
*/
private static Map<String, Object> instanceCache = new ConcurrentHashMap<>();
/**
* 系统 SPI 目录
*/
private static final String RPC_SYSTEM_SPI_DIR = "META-INF/rpc/system/";
/**
* 用户自定义SPI目录
*/
private static final String RPC_CUSTOM_SPI_DIR = "META-INF/rpc/custom/";
/**
* 扫描路径
*/
private static final String[] SCAN_DIRS = new String[]{
RPC_SYSTEM_SPI_DIR,
RPC_CUSTOM_SPI_DIR,
};
/**
* 动态加载的类列表
*/
private static final List<Class<?>> LOAD_CLASS_LIST = Arrays.asList(Serializer.class);
/**
* 加载所有类型
*/
public static void loadAll() {
log.info("加载所有的SPI");
for (Class<?> aClass : LOAD_CLASS_LIST) {
load(aClass);
}
}
/**
* 加载某个类型
*
* @param loadClass
* @return
*/
public static Map<String, Class<?>> load(Class<?> loadClass) {
log.info("加载类型为 {} 的SPI", loadClass.getName());
// 扫描路径,用户自定义的SPI 优先级高于系统SPI
HashMap<String, Class<?>> keyClassMap = new HashMap<>();
for (String scanDir : SCAN_DIRS) {
log.info("扫描路径为 {}", scanDir + loadClass.getName());
List<URL> resources = ResourceUtil.getResources(scanDir + loadClass.getName());
// 读取每个资源文件
for (URL resource : resources) {
try {
InputStreamReader inputStreamReader = new InputStreamReader(resource.openStream());
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line;
while ((line = bufferedReader.readLine()) != null) {
String[] split = line.split("=");
if (split.length < 2) {
log.error("SPI配置文件格式错误");
continue;
}
String key = split[0];
String className = split[1];
log.info("加载 {} SPI配置文件 key={} className={}",
scanDir.equals(RPC_CUSTOM_SPI_DIR) ? "自定义" : "系统", key, className);
keyClassMap.put(key, Class.forName(className));
}
} catch (Exception e) {
log.error("加载SPI配置文件失败", e);
}
}
}
loaderMap.put(loadClass.getName(), keyClassMap);
return keyClassMap;
}
/**
* 获取某个类型的实例
*
* @param tClass
* @param key
* @param <T> 类型
*/
public static <T> T getInstance(Class<?> tClass, String key) {
String tClassName = tClass.getName();
Map<String, Class<?>> keyClassMap = loaderMap.get(tClassName);
if (keyClassMap == null) {
throw new RuntimeException(String.format("SpiLoader 未加载%s 类型", tClassName));
}
if (!keyClassMap.containsKey(key)) {
throw new RuntimeException(String.format("SpiLoader 的 %s不存在 key= %s", tClassName, key));
}
// 获取到要加载的实现类型
Class<?> implClass = keyClassMap.get(key);
// 从实例缓存中加载指定类型的实例
String implClassName = implClass.getName();
if (!instanceCache.containsKey(implClassName)) {
try {
instanceCache.put(implClassName, implClass.newInstance());
} catch (InstantiationException | IllegalAccessException e) {
String format = String.format("实例化 %s 失败", implClassName);
throw new RuntimeException(format, e);
}
}
return (T) instanceCache.get(implClassName);
}
}
对代码的一些解释:
/**
* 存储已加载的类:接口名=>(key=>实现类)
*/
private static Map<String, Map<String, Class<?>>> loaderMap = new ConcurrentHashMap<>();
/**
* 对象实例缓存 避免重放new 类路径=> 对象实例 ,单例模式
*/
private static Map<String, Object> instanceCache = new ConcurrentHashMap<>();
- 这里的loaderMap是存放
接口=>实现类的映射 - instanceCache是存放
key对应的类的实例
InputStreamReader inputStreamReader = new InputStreamReader(resource.openStream());
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line;
while ((line = bufferedReader.readLine()) != null) {
String[] split = line.split("=");
if (split.length < 2) {
log.error("SPI配置文件格式错误");
continue;
}
String key = split[0];
String className = split[1];
keyClassMap.put(key, Class.forName(className));
}
这里 是按行读取,用=分割,
例如读取到的结果为:jdk=com.yunfei.rpc.serializer.JdkSerializer
然后使用Class.forName(className)进行动态加载类,className为 com.yunfei.rpc.serializer.JdkSerializer
Class.forName(className)方法只是返回一个表示指定类的Class对象,并不会实例化这个类的对象。
返回 Class 对象
Class.forName(className)方法会根据传入的类名动态加载并返回一个Class对象。- 这个
Class对象可以用来进行各种反射操作,如获取类的成员、创建实例等。不会实例化对象
Class.forName(className)方法只是加载并返回Class对象,并不会创建该类的实例。- 如果要创建类的实例,需要使用
Class对象的newInstance()方法或通过构造函数反射来实例化。
在 SPI 加载器的实现中,Class.forName(className) 只是用来加载 SPI 实现类的 Class 对象,并将其存储在 keyClassMap 中。真正的实例化操作是在 getInstance() 方法中完成的,通过 newInstance() 或反射的方式创建 SPI 实现类的实例,并缓存起来。
这种分离加载和实例化的设计,可以让 SPI 加载器更加灵活和高效。只有当需要使用 SPI 实现时,才会触发实例化操作,避免了不必要的资源消耗。具体的代码如下 :
// 获取到要加载的实现类型
Class<?> implClass = keyClassMap.get(key);
// 从实例缓存中加载指定类型的实例
String implClassName = implClass.getName();
if (!instanceCache.containsKey(implClassName)) {
try {
instanceCache.put(implClassName, implClass.newInstance());
} catch (InstantiationException | IllegalAccessException e) {
String format = String.format("实例化 %s 失败", implClassName);
throw new RuntimeException(format, e);
}
}
return (T) instanceCache.get(implClassName);
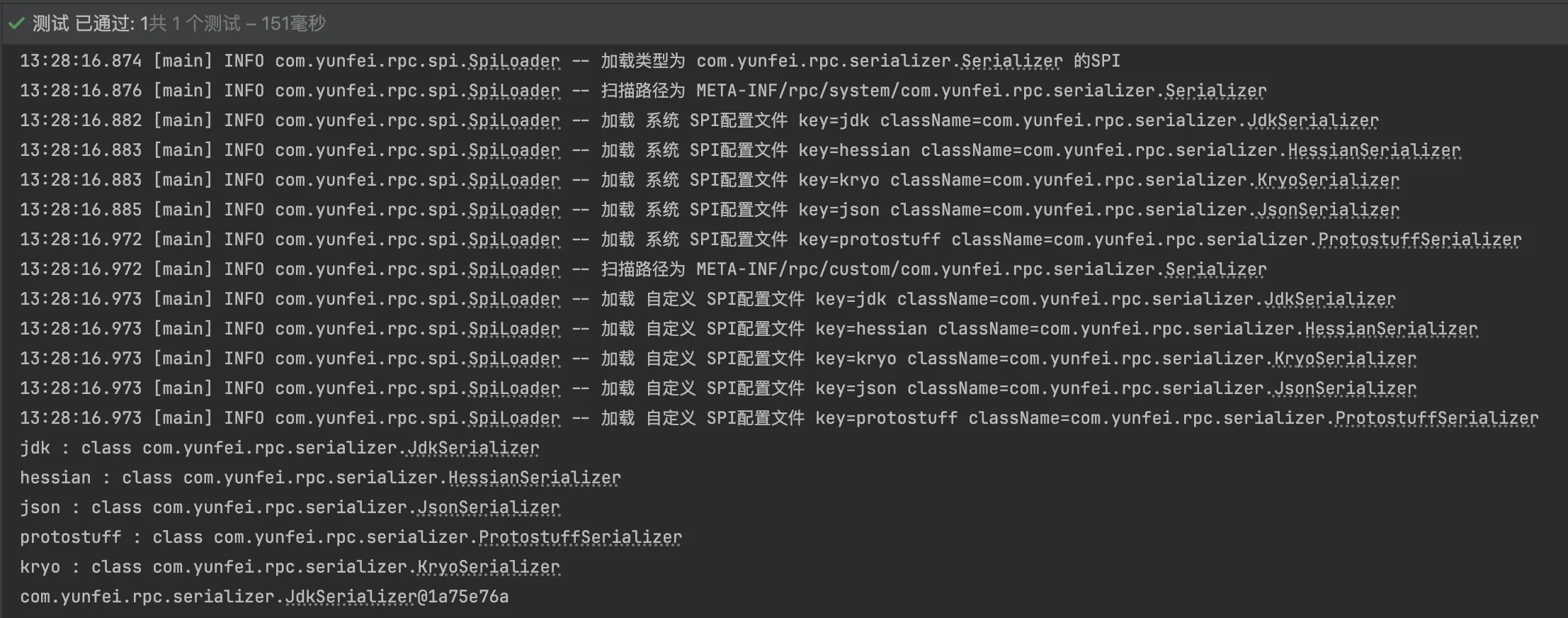
测试:
@Test
void load() {
Map<String, Class<?>> classMap = SpiLoader.load(Serializer.class);
for (Map.Entry<String, Class<?>> entry : classMap.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
@Test
void getInstance() {
this.load();
Object jdk = SpiLoader.getInstance(Serializer.class, "jdk");
System.out.println(jdk);
}
运行结果,可以看到先扫描系统目录,再扫描用户目录,会覆盖系统设置,同时也可以获取 到实例对象:
针对Serializer使用工厂单例模式:
public class SerializerFactory {
static {
SpiLoader.load(Serializer.class);
}
/**
* 获取序列化器
*/
public static Serializer getInstance(String key) {
return SpiLoader.getInstance(Serializer.class, key);
}
}